RAG for Law Firms: The Complete Guide
What RAG means for legal knowledge management, how it works, where it fits, and what to evaluate. The definitive resource for law firms exploring AI-powered document intelligence.
Law firms sit on decades of accumulated intelligence — contracts, precedents, policies, case files, memos, and institutional knowledge built deal by deal, matter by matter. The knowledge is there. It's just not accessible, trustworthy, or current. Partners retire and take expertise with them. Templates reference superseded authority. Associates spend hours searching five systems for a clause they know exists somewhere. As we explored in "Is This the Latest Template?" Why Law Firm Knowledge Bases Fail, traditional document management stores files but doesn't maintain knowledge. RAG for law firms changes what's possible. Retrieval-Augmented Generation is AI that retrieves answers from your firm's actual documents — with source citations — rather than generating text from training data. Every answer is grounded in what your firm has written, not in what a model was trained on.
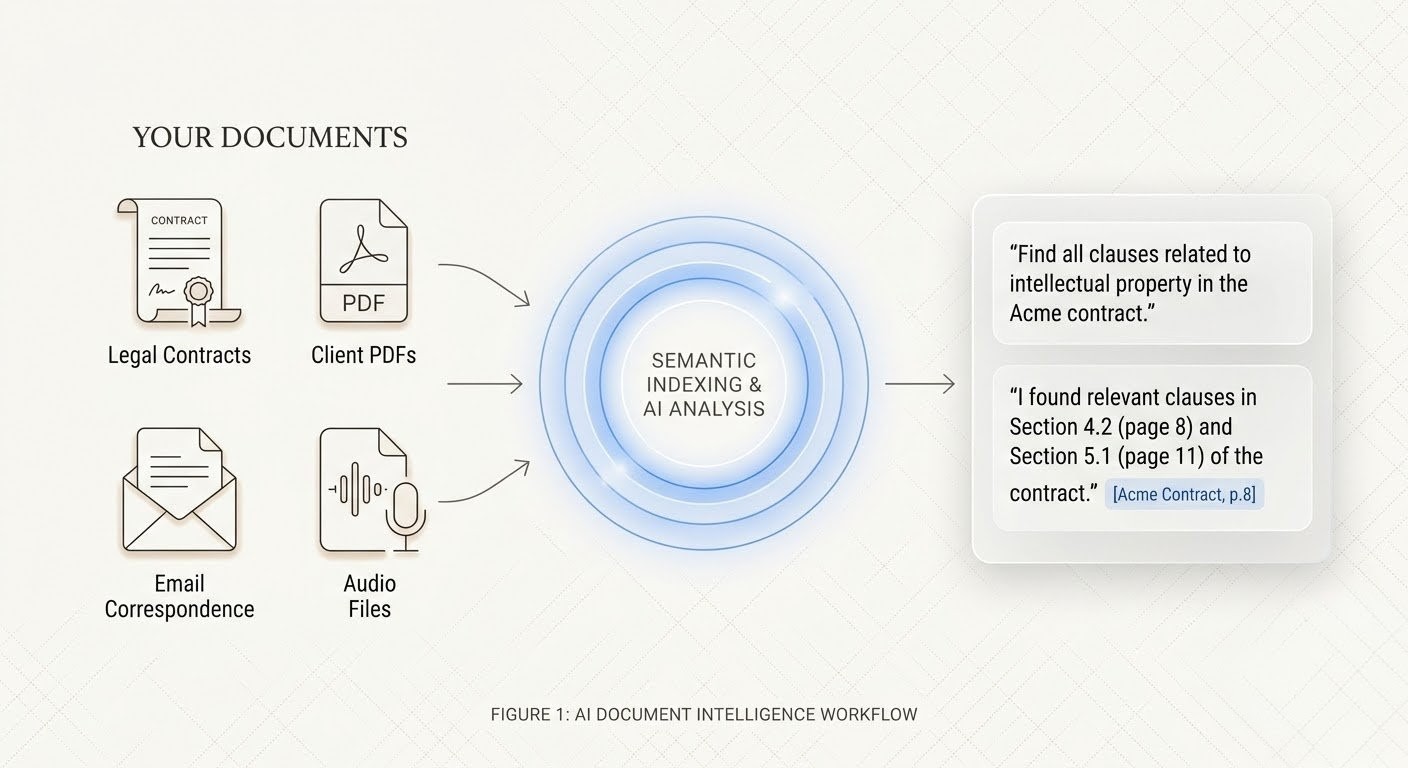
What RAG Actually Means for Legal Teams
The legal profession has watched the generative AI wave with justified skepticism. The core concern isn't whether AI can produce text — it's whether that text can be trusted. For a profession built on precision, attribution, and defensibility, the distinction between generation and retrieval isn't a technical nuance. It's the entire point.
RAG Retrieves. It Doesn't Generate.
The fundamental difference between RAG and conventional large language models is simple: RAG doesn't make things up. When an attorney asks "What limitation of liability cap did we use in the 2024 Meridian SaaS agreement?", a RAG system searches your firm's indexed documents, identifies the relevant clause, and presents it with a citation pointing to the exact document, page, and section. The answer comes from your files. If the answer isn't in your documents, the system says so — rather than fabricating one.
This matters for legal work in ways it doesn't for other industries. Source attribution on every response means answers are verifiable. No hallucination means no fabricated case citations, no invented contract terms, no phantom precedents. Defensible answers mean that when a client asks "Where did this come from?", you can point to the source — because the system already did.
The "ChatGPT Problem"
The risk of ungrounded AI in legal practice isn't hypothetical. A Stanford study found that even purpose-built legal AI tools hallucinate 17–33% of the time — fabricating case citations, inventing holdings, or misrepresenting procedural history. The consequences have already materialized: a New York attorney was sanctioned by the court for submitting a brief citing cases that ChatGPT fabricated entirely. The cases didn't exist. The holdings were invented. The courts cited were real, but the decisions were not.
RAG eliminates this class of failure by design. There is no generation from training data. There is only retrieval from your documents — with citations that point to real, verifiable sources.
How RAG Works — A Technical Primer for Non-Technical Lawyers
RAG isn't magic. It's a pipeline — a sequence of well-defined steps that transform static documents into a queryable knowledge system. Understanding these steps helps evaluate whether a platform genuinely delivers intelligent retrieval or simply wraps keyword search in better marketing.
Document Ingestion
The pipeline begins by absorbing your documents — contracts, memos, briefs, policies, templates, email, and any other text your firm has produced. Enterprise RAG platforms handle the full range of formats law firms actually use: native PDFs, scanned PDFs (via OCR), Word documents, spreadsheets, presentations, and plain text. Hybrid parsing is essential for older scanned filings where standard text extraction produces garbled results — combining OCR, layout analysis, and post-processing to produce clean, accurate text from documents that might be decades old.
Semantic Indexing
Once ingested, each document is broken into meaningful chunks — typically at the clause, paragraph, or section level — and converted into mathematical representations called vector embeddings. These embeddings capture meaning, not just keywords. "Unlimited indemnification" and "liability cap" share no common words, but a properly indexed system understands they're semantically related — that one might contradict the other. This is what separates semantic search from the keyword search built into every DMS: the system understands that "vendor shall defend and hold harmless without limitation" relates to "aggregate exposure shall not exceed total fees paid," even though those phrases share zero terminology.
Query and Retrieval
When an attorney asks a natural language question — "What termination-for-convenience provisions exist across our vendor agreements?" — the system converts that question into the same embedding space, identifies the most semantically relevant document chunks, and assembles them into a coherent, cited answer. The retrieval is contextual: the system doesn't just find documents that mention "termination." It finds the specific provisions that address termination for convenience, distinguishing them from termination for cause, termination upon insolvency, and every other variation.
Source Attribution
Every answer traces back to its source. Not just the document name — the page, the section, the specific clause. When the system tells you that the Meridian SaaS agreement caps liability at twelve months of fees paid, it cites Section 12.2 of that agreement. An attorney can verify the finding in seconds rather than hours. This isn't a design preference — it's a professional obligation. Lawyers cannot rely on answers they cannot verify, and RAG systems are built around this constraint.
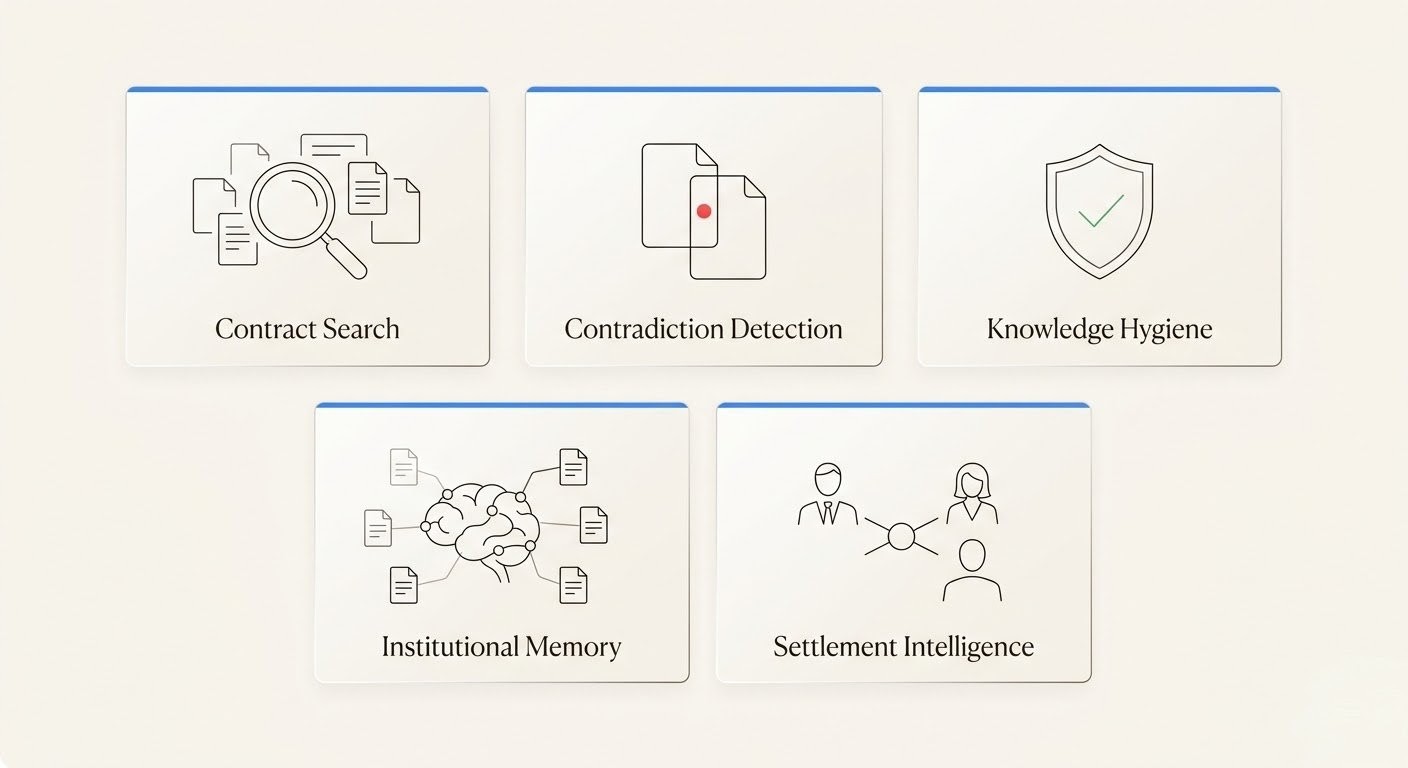
Five Use Cases Where RAG Transforms Legal Work
RAG is a capability, not a feature. Its value depends on where you apply it. These five use cases represent the highest-impact applications for law firms — each grounded in verified data on the problems they solve.
Contract Portfolio Search
Finding contracts shouldn't be a research project. But DocuSign's contract analysis research found that contract professionals spend an average of 45 minutes to find a contract and 84 minutes to find specific language within one. Across a firm handling thousands of contracts, that's thousands of hours annually spent on retrieval — time billed to clients at reduced rates or written off entirely.
RAG transforms contract search from a multi-system scavenger hunt into a single query. "Which vendor agreements contain unlimited indemnification provisions?" returns every relevant clause across the entire portfolio, with citations, in seconds. No opening five systems. No guessing which folder a partner saved it to. No asking the associate who "just knows."
Contradiction Detection
Contracts assembled by multiple drafters accumulate contradictions — and the consequences are measured in nine figures. As we analyzed in How AI Can Detect Conflicting Clauses Before They Become Litigation, a single copy-pasted clause contributed to $636 million in client losses in the Proskauer Rose malpractice case. The clause wasn't invented — it was copied from a prior deal where it made sense. It just didn't belong in this one.
RAG-based contradiction detection maps semantic relationships between clauses — indemnification provisions against liability caps, termination triggers against notice requirements, governing law against jurisdiction clauses — and flags conflicts with source citations. Not just within a single document, but across master agreements, amendments, SOWs, and side letters that accumulate over years of a contractual relationship.
Knowledge Hygiene
Legal knowledge decays silently. Templates reference superseded case law. Compliance checklists cite outdated regulations. Precedent documents incorporate procedural standards that courts no longer accept. iManage's 2026 Benchmark Report found that 72% of organizations plan DMS upgrades, with governance concerns as a primary driver — an implicit acknowledgment that current systems aren't maintaining knowledge integrity.
RAG platforms with proactive maintenance capabilities continuously scan indexed documents for staleness indicators: outdated statutory references, superseded regulatory citations, expired contractual terms, and provisions that conflict with more recently executed agreements. Instead of discovering that a template is wrong when opposing counsel points it out, the system flags it before anyone uses it.
Institutional Memory Capture
The most valuable knowledge at any firm lives in the heads of its most experienced attorneys — and it walks out the door every time someone retires, laterals, or burns out. LawCare's Life in the Law survey found that 60% of legal professionals report poor mental wellbeing, and 56% may leave the profession within five years. That's not just a wellness crisis — it's a knowledge management emergency.
RAG systems capture institutional knowledge by making it queryable. When a senior partner's deal memos, negotiation notes, and marked-up templates are indexed and searchable, their expertise persists in the system even after they leave. A junior associate can ask "How did we handle force majeure carve-outs in our pharmaceutical licensing deals?" and receive answers drawn from twenty years of the partner's work — with citations to the specific documents. The knowledge stops being a person and becomes a retrievable asset.
Mediation and Settlement Intelligence
Mediation outcomes depend on understanding precedent — not just case law precedent, but the firm's own history of settlement positions, mediation strategies, and outcome data. The IBA's 2024 Guidelines on the Use of Generative AI in Mediation specifically identify AI's role in document synthesis and settlement drafting as an emerging capability that mediators and legal teams should understand.
RAG enables attorneys to query the firm's entire mediation history: "What settlement ranges have we achieved in employment discrimination mediations in the Southern District?" The system retrieves relevant settlement memos, mediation briefs, and outcome records — surfacing patterns that would take weeks of manual research to identify. Data-informed negotiation strategy, grounded in your firm's actual experience.
What to Evaluate When Choosing a Legal RAG Platform
Not all RAG platforms are built for legal. The requirements of a profession governed by privilege, confidentiality, and malpractice exposure are materially different from those of a marketing team searching a content library. Here's what to evaluate.
Document support. Can the platform handle the documents your firm actually has — including scanned PDFs from the 1990s, legacy Word formats, and OCR-resistant filings? Hybrid parsing that combines multiple extraction methods is essential for firms with large historical archives.
Security architecture. On-premise deployment options. Data isolation between matters and clients. Zero-training guarantees — your documents must never be used to train the underlying AI models. For firms handling privileged communications, this isn't negotiable. Integris research found that 81% of clients cite data protection as their primary concern when law firms adopt generative AI. Your platform needs to address this with architecture, not assurances.
Source attribution quality. Does the system cite at the page and section level, or just the document level? Attorneys need to verify findings against source text. A citation that says "see Meridian SaaS Agreement" is minimally useful. A citation that says "Section 12.2, page 47, Meridian SaaS Agreement dated March 2024" is actionable.
Contradiction detection. Can the system identify conflicts within documents and across portfolios? Intra-document contradiction detection is the baseline. Cross-document detection — flagging conflicts between a master agreement and an amendment executed two years later — is where the real value lies.
Knowledge maintenance. Does the platform proactively detect staleness, or does it passively store whatever you feed it? A system that flags outdated regulatory references and superseded case law citations before someone relies on them is fundamentally different from one that simply returns whatever's in the index.
Integration. DMS connectors for iManage and NetDocuments. API access for custom workflows. MCP (Model Context Protocol) support for integration with other AI tools in your stack. The platform needs to work with your existing infrastructure, not require you to abandon it.
Deployment model. Cloud, on-premise, or hybrid. Firms with strict data residency requirements need on-premise options. Firms optimizing for speed of deployment may prefer cloud. The right answer depends on your security posture and regulatory environment.
Where Mojar Fits — Honest Positioning
Mojar is an enterprise RAG platform designed to transform static document repositories into intelligent, queryable knowledge systems. Here's what it does, what it doesn't do, and when it's the right choice.
What Mojar does. Universal document ingestion — including scanned PDFs, legacy formats, and voice recordings converted to searchable embeddings. Semantic search with source attribution at the section and clause level. Autonomous contradiction detection across documents and portfolios. A document maintenance agent that proactively identifies staleness, outdated references, and knowledge decay. MCP integration for interoperability with other AI systems in your workflow.
What Mojar doesn't do (yet). Native iManage and NetDocuments connectors are on the roadmap but not yet in production. Real-time case law update feeds — automatically flagging when indexed documents cite authority that has been overturned or modified — are in active development. Direct CLM integration with platforms like Ironclad is planned but not available today. We'd rather tell you this now than have you discover it during implementation.
When Mojar is the right fit. Firms with large historical document portfolios that need knowledge integrity, not just search. Organizations where institutional knowledge is concentrated in a small number of senior attorneys approaching retirement or lateral transitions. Practice groups assembling contracts from clause libraries maintained by multiple teams, where contradiction risk is high. Any firm that has experienced the consequences of an outdated template, a conflicting clause, or a knowledge base that nobody trusts.
When it's not. Pure eDiscovery needs — Relativity is purpose-built for that. Document drafting from scratch — that's a generative AI use case, not a retrieval one. Firms that just need a better DMS without AI-powered analysis — a DMS upgrade may be the simpler and more appropriate solution.
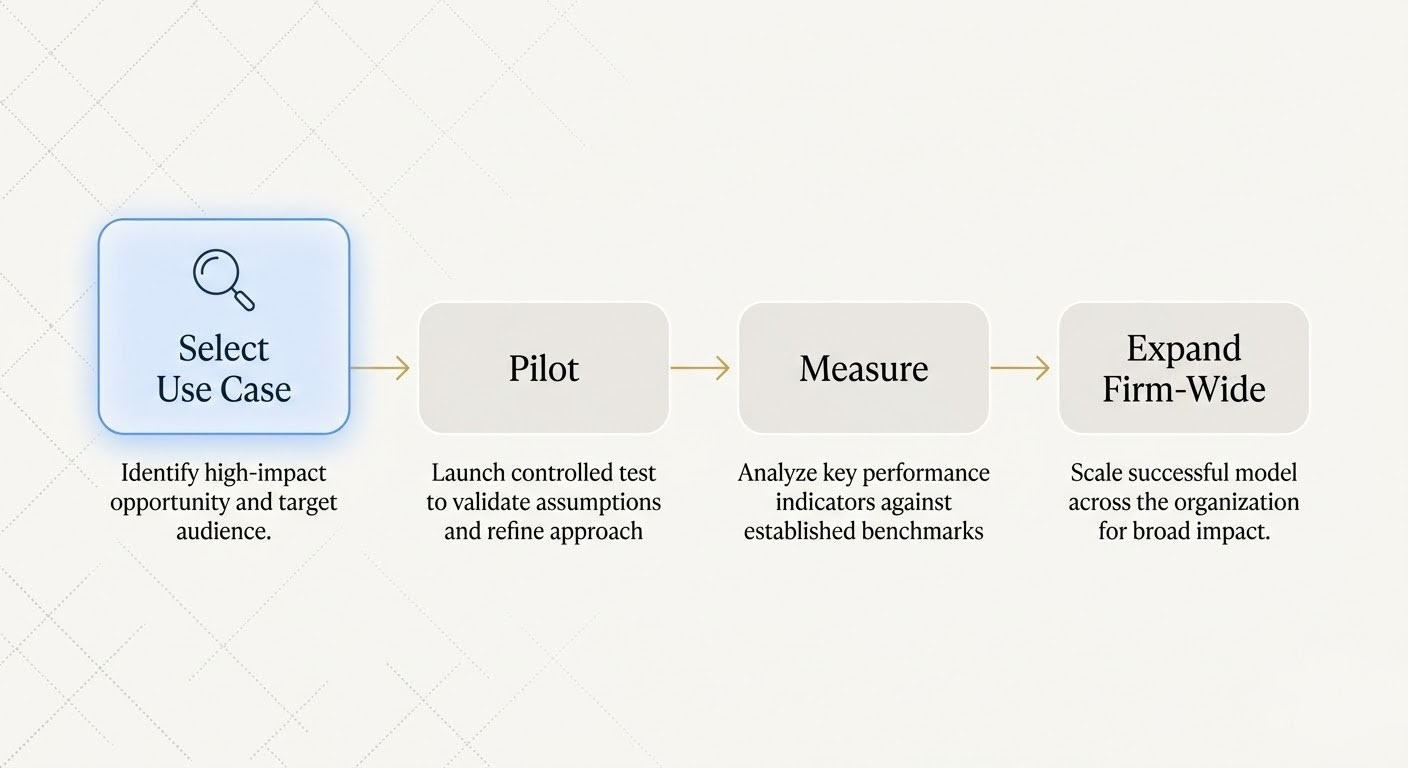
Getting Started — A Pragmatic Roadmap
The firms that succeed with RAG don't try to index everything on day one. They start small, measure results, and expand based on evidence — not vendor promises.
Start with one practice group or one use case. Contract portfolio search is typically the highest-ROI starting point: it addresses a universal pain point (finding clauses across thousands of agreements), delivers measurable time savings, and produces results attorneys can verify immediately. Pick the practice group with the largest document volume and the most vocal complaints about search.
Pilot for 2–4 weeks with real documents. Not demo data — your actual contracts, memos, and templates. The pilot should answer a concrete question: does this system find what our attorneys need, faster and more accurately than our current process? If it doesn't work with your documents, it doesn't work.
Measure what matters. Time saved per search. Contradictions identified that would have been missed. Attorney satisfaction — do they actually use the system voluntarily after the first week? The metrics should be practical and tied to outcomes your firm already cares about: utilization rates, write-off reduction, and risk mitigation.
Expand based on results, not promises. If the pilot delivers measurable value in corporate, extend to litigation. If contract search works, add contradiction detection. Each expansion should be justified by the evidence from the prior phase — not by a slide deck about what the platform could theoretically do.
Next Steps
RAG is not a future technology for law firms. It's a current capability — already deployed, already delivering results, already changing how firms manage and trust their knowledge.
Go deeper on contradiction detection: How AI Can Detect Conflicting Clauses Before They Become Litigation examines the specific mechanics of finding conflicts across contract portfolios.
Understand why knowledge bases fail: "Is This the Latest Template?" Why Law Firm Knowledge Bases Fail explores the root causes of knowledge decay and fragmentation that RAG is designed to solve.
Explore compliance documentation: The Audit Scramble: Why Legal Teams Panic When Documentation Is Requested covers the documentation integrity challenges that RAG addresses proactively.
See RAG with your firm's documents — no credit card required. Start your free trial and run semantic search against your actual contracts, memos, and templates. Find out what's in your knowledge base — and what's hiding in it.
Frequently Asked Questions
RAG (Retrieval-Augmented Generation) is AI that retrieves answers from your firm's actual documents with source citations, rather than generating text from training data. Every answer is grounded in your knowledge base — not invented. When an attorney asks 'What indemnification cap did we use in the Meridian deal?', RAG finds the exact clause, cites the document and section, and presents the answer with provenance.
ChatGPT generates text from training data — it doesn't know what's in your contracts, templates, or memos. A Stanford study found that even purpose-built legal AI tools hallucinate 17–33% of the time. RAG eliminates this by grounding every answer in your firm's actual documents. ChatGPT generates; RAG retrieves.
RAG platforms can index contracts, templates, briefs, memos, policies, court filings, email, meeting notes, and precedent libraries. Supported formats include PDF (including scanned documents via OCR), Word, spreadsheets, and presentations. Enterprise platforms use hybrid parsing to handle older scanned documents that standard text extraction can't process.
Pilot deployments typically run 2–4 weeks for a single practice group. Firm-wide rollout varies by document volume and integration requirements. The key is starting with a specific use case — such as contract portfolio search — rather than trying to index everything at once.
Thomson Reuters projects that generative AI will free up 240 hours per year per legal professional. Frame ROI as: minutes saved per search × searches per day × billing rate = direct margin recovery. In one documented case study, a firm reported £680K in annual capacity gains after deploying an AI-powered knowledge system — capacity that translated directly to additional billable work and reduced write-offs.
No. RAG sits on top of iManage, NetDocuments, SharePoint, and other DMS platforms. It adds intelligence to existing storage — semantic search, contradiction detection, freshness tracking. It complements your DMS, doesn't replace it.
Data security is the primary concern for 81% of clients when law firms use generative AI (Integris). Enterprise RAG platforms address this with on-premise deployment options, strict data isolation, and zero-training guarantees — your documents are never used to train AI models. Your data never leaves your environment.